Bun vs Go for Streaming LLM Agent Runtime: A Raw Benchmark
Updated June 20, 2026
Published June 20, 2026

Well, you may have heard that they rewrote Bun in Rust and merged over 1 million lines of code to main back in May. See this PR to witness the moment in history.
Before that, there was Anton Putra's Go vs Bun comparison video and
The PrimeTime's reaction to that video. After watching both, I got inspired, got curious, and wanted to run my own version with a workload closer to what I actually build day to day. Anton's video only covers DB CRUD but never touches SSE streaming though, so I thought this was definitely worth checking out.
If you're building an LLM agent, most of the behavior looks the same no matter what framework you pick, whether it's LangChain,
LangGraph, or Langchiggity-whatever-else. You run a while loop while the model yields tokens, and your runtime streams them back to the client in whatever format your frontend can plug into a pretty UI.
Either way, the bottleneck usually isn't your code, it's the model itself. At the time I'm writing this (June 2026), we still don't have enough GPU power to serve models the way we have bandwidth for broadband internet. Even if you build the backend in the most performant language on earth, the model is still what slows you down.
But your runtime still has to keep a lot of those slow, long-lived streaming connections open at once without falling over. That part is on you, and it's where the language you pick starts to matter.
So I put Bun and Go head to head on the same job, each one running nothing but the HTTP server built into the runtime.
The setup
No framework. Just the lowest-level HTTP primitive each runtime ships with:
- Go:
net/http(stdlib) - Bun:
Bun.serve()
| CPU | 4 × Intel® Core™ i5-7300HQ CPU @ 2.50GHz |
| RAM | 8 GiB |
| OS | CachyOS 7.0.12 |
| Go version | 1.26.4 |
| Bun version | 1.3.13 |
Both servers expose the same contract:
POST /chat{ "message": "hello" }Each request follows the same path: take the incoming message, send it to the stub, and stream the response back to the client token by token until the stub signals it's done. No database, no middleware, nothing else in between.
The stub is a tiny Go server standing in for OpenAI's
/chat/completions endpoint. It returns a fixed number of SSE tokens with a small delay between each one, so the server under test has to keep the connection open and wait the same way it would against a real model.
The tools I used:
k6 to generate the load and verify every response came back
200with a[DONE]at the end of the streampidstat (from the sysstat package) to sample CPU and memory once a second, measured against the actual server PID rather than the
go runwrapper (more on that later)gnuplot to plot those samples into the charts further down
Here's the raw k6 output from each run. Both passed every check, and the ~1 second response time is just the stub's token delay, not the server struggling.
Go
1 /\ Grafana /‾‾/2 /\ / \ |\ __ / /3 / \/ \ | |/ / / ‾‾\4 / \ | ( | (‾) |5 / __________ \ |_|\_\ \_____/6 7 8 execution: local9 script: k6/baseline.js10 output: -11 12 scenarios: (100.00%) 1 scenario, 10 max VUs, 1m30s max duration (incl. graceful stop):13 * default: 10 looping VUs for 1m0s (gracefulStop: 30s)14 15 16 17 █ TOTAL RESULTS18 19 checks_total.......: 1180 19.665/s20 checks_succeeded...: 100.00% 1180 out of 118021 checks_failed......: 0.00% 0 out of 118022 23 ✓ status 20024 ✓ has DONE25 26 HTTP27 http_req_duration..............: avg=1.01s min=1.01s med=1.01s max=1.02s p(90)=1.01s p(95)=1.02s28 { expected_response:true }...: avg=1.01s min=1.01s med=1.01s max=1.02s p(90)=1.01s p(95)=1.02s29 http_req_failed................: 0.00% 0 out of 59030 http_reqs......................: 590 9.8325/s31 32 EXECUTION33 iteration_duration.............: avg=1.01s min=1.01s med=1.01s max=1.02s p(90)=1.01s p(95)=1.02s34 iterations.....................: 590 9.8325/s35 vus............................: 10 min=10 max=1036 vus_max........................: 10 min=10 max=1037 38 NETWORK39 data_received..................: 918 kB 15 kB/s40 data_sent......................: 96 kB 1.6 kB/sBun
1 /\ Grafana /‾‾/2 /\ / \ |\ __ / /3 / \/ \ | |/ / / ‾‾\4 / \ | ( | (‾) |5 / __________ \ |_|\_\ \_____/6 7 8 9 execution: local 10 script: k6/baseline.js 11 output: - 12 13 scenarios: (100.00%) 1 scenario, 10 max VUs, 1m30s max duration (incl. graceful stop): 14 * default: 10 looping VUs for 1m0s (gracefulStop: 30s) 15 16 17 18 █ TOTAL RESULTS 19 20 checks_total.......: 1200 19.704167/s 21 checks_succeeded...: 100.00% 1200 out of 1200 22 checks_failed......: 0.00% 0 out of 1200 23 24 ✓ status 200 25 ✓ has DONE 26 27 HTTP 28 http_req_duration..............: avg=1.01s min=1s med=1.01s max=1.02s p(90)=1.01s p(95)=1.01s 29 { expected_response:true }...: avg=1.01s min=1s med=1.01s max=1.02s p(90)=1.01s p(95)=1.01s 30 http_req_failed................: 0.00% 0 out of 600 31 http_reqs......................: 600 9.852084/s 32 33 EXECUTION 34 iteration_duration.............: avg=1.01s min=1s med=1.01s max=1.02s p(90)=1.01s p(95)=1.01s 35 iterations.....................: 600 9.852084/s 36 vus............................: 10 min=10 max=10 37 vus_max........................: 10 min=10 max=10 38 39 NETWORK 40 data_received..................: 934 kB 15 kB/s 41 data_sent......................: 98 kB 1.6 kB/sWhat I measured
This run was 10 virtual users sending requests for a minute, no database, just the proxy path. The CPU and memory came out clean:
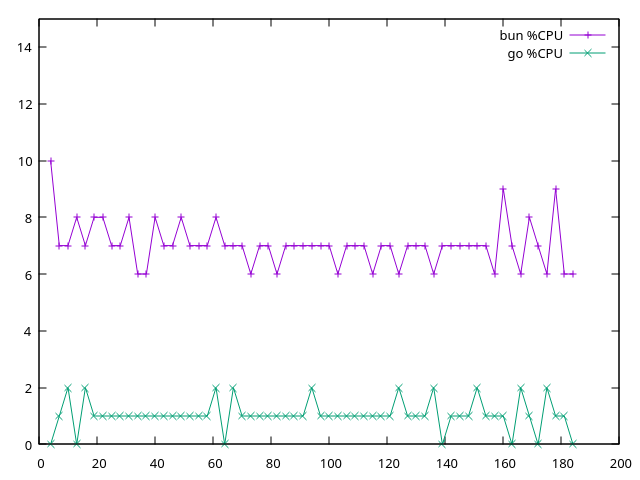
CPU (%CPU, one sample per second):
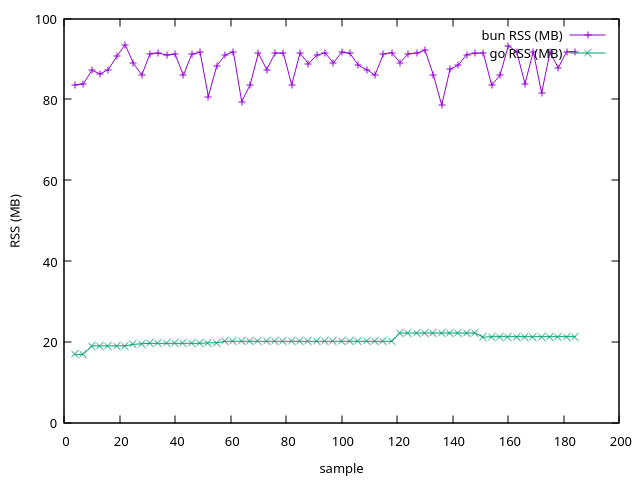
Memory (RSS, MB):
| Go | Bun | |
|---|---|---|
| CPU usage | ~0-2% | ~6-9% |
| RSS memory | ~17-22 MB | ~85-92 MB |
Go used roughly 4x less memory than Bun and stayed near zero on CPU doing the same work. It wasn't close.
What this run actually covers
To be clear about the scope: this was the lightest version of the test I could run. 10 users, one minute, one message each, no database, no real model, just the proxy path streaming fake tokens. It only tells you how each runtime behaves when it is barely working.
What I still want to do:
- run k6's stress profile (ramping to 200 users) to find where each one starts to break down
- run a soak test (sustained load for 10+ minutes) to catch any slow memory growth
- wire up the chat history path I keep mentioning
So Go won. Is it settled?
Not really. A real agent runtime has to handle a lot more than what I tested here:
- multiple tool calls, parallel or sequential
- a long-running agentic loop that runs several turns on its own
- sub-agent spawning (Go should do well here)
- multimodal input and output
- full CRUD on chat threads
- streaming pub/sub
Those are the parts that decide whether a runtime holds up in production, and I haven't tested any of them.
There's also the ecosystem, which no benchmark shows. Bun, TypeScript and Python have far more AI tooling today: streaming helpers, tool-calling libraries, SDKs built for the language. Go's small footprint doesn't help much if it takes three times as long to build the agent because the library you want only ships for Node and Python.
So Go wins on raw numbers, clearly. Whether that matters to you depends on what you're optimizing for: the cloud bill, or how fast you can ship.
Would I still choose Bun?
TL;DR:
Choose Bun (or even Python) if:
- You wanna ship fast
- You wanna keep up with the latest innovations in AI (see every agentic framework like LangThis, LangThat, they all ship as a JS or Python package first since those are the most popular languages for this stuff)
- You run on serverless and don't care about cold starts or resource usage
- You're not serving a high-traffic production workload, think internal-use chatbot or an agent popup on an existing SaaS product (which is hard to access anyway)
- Even if you do need to scale Bun (or a slow a$$ language like Python), you can always throw money at the scaling problem, lol
Choose Go if:
- Your team is already familiar with Go
- You're serving a high-traffic production workload (I'm talking millions of RPS like
ChatGPT, not Theo Browne's
t-something chat)
- You care about resource cost at scale and don't want your cloud bill running its own agentic loop
- You want a single static binary you can just ship, no runtime to install, no node_modules folder bigger than the app itself lol
- Cold start time actually matters to you (Go boots instantly on serverless, Bun and Node not so much)
Notes
This experiment is maybe 1% of what I actually want to do. Next I want to bring in other fast languages like Rust and C++, and compare things at the framework level too, like
LangChain JS,
LangChain Python,
Vercel AI SDK and
Eino. All the code lives
here if you want to run it yourself.
 puvish.dev, All Rights Reserved.
puvish.dev, All Rights Reserved.